IRL HTML Is the Place For Your Most Hand-Written Websites
Last year before HTML Energy's HTML Day in San Francisco I had the idea to iterate on some of my previous projects like Whiteboard Email, and make both an app that would do OCR on HTML, and a website to host truly “hand-written” HTML. That became IRL HTML and it was good enough to make some very simple websites!
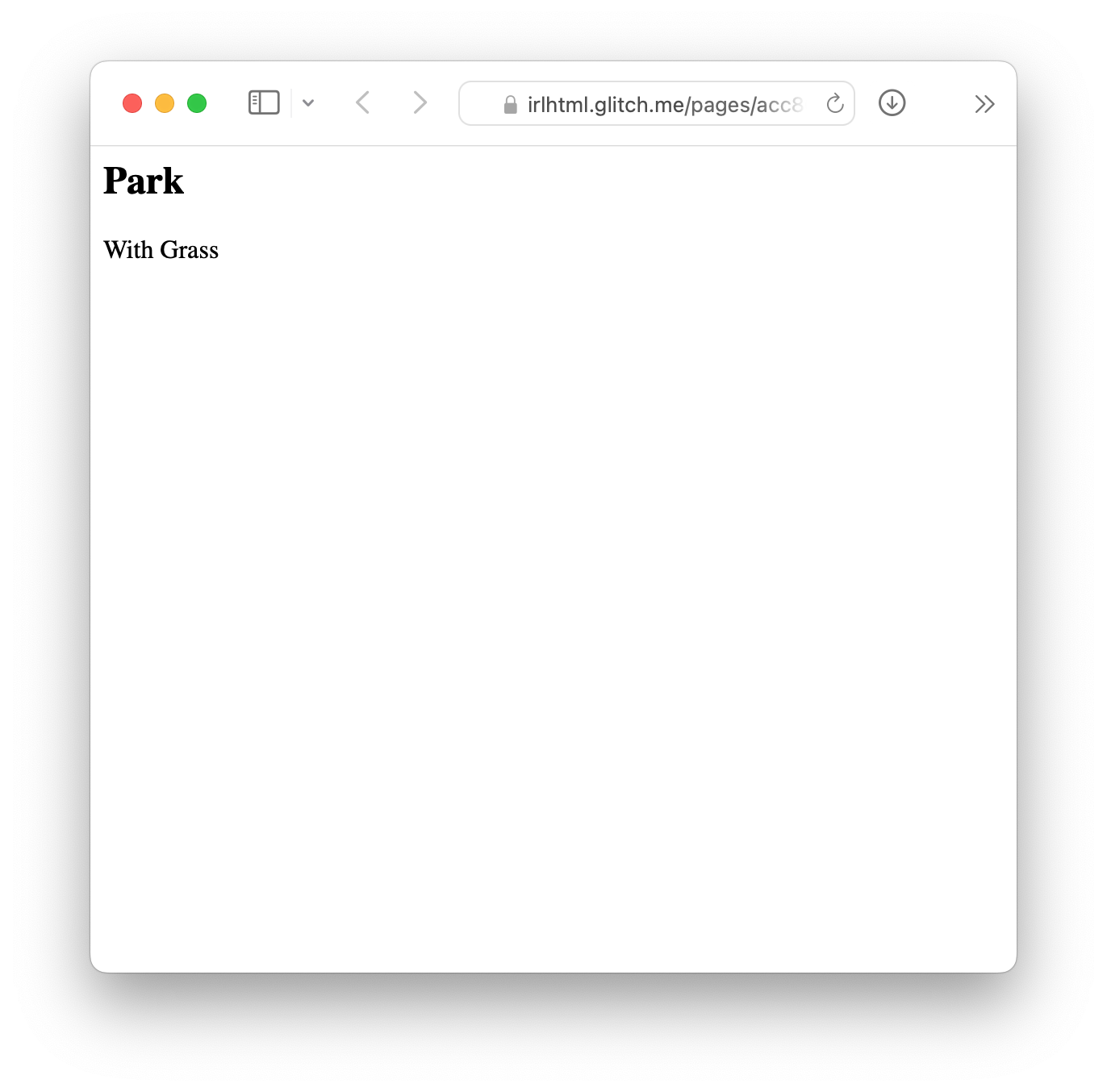

The first prototype of IRL HTML used Tesseract.js which is only reliable for typewritten text. Given my success with album covers I tried the Google Vision API, which worked well enough for some (carefully) hand-written HTML, but still made a lot of errors, which might prevent the page from rendering at all.
A lot of the projects I’ve done over the years have used computer vision in creative ways, and I’ve always been searching for more reliable ways to have computers read hand-written text. At a Recurse Center meetup in SF in January 2024 someone suggested that the ChatGPT API might be capable of it. We made a simple website on IRL HTML to commemorate the occasion.
To get ready for the 2024 HTML Day I decided to update IRL HTML using both the ChatGPT and Anthropic Claude APIs. Both were able to read my hand-written HTML code surprisingly well! They do sometimes output text that isn’t really there (notice the <ul> tags were turned into <p> tags in the example below), and sometimes it adds some description of the output, which for this case isn’t useful. One benefit of the multi-modal nature of the LLMs is that I can inform the model that the output is supposed to be HTML, I can add instructions to fix any minor syntax errors. I could probably improve the accuracy even more by combining OCR methods, or making multiple requests to the LLMs.
The prompt I’m using for both LLM APIs is:
This is an image of a piece of paper with HTML code on it. If there are any syntax errors, fix them with the most likely valid HTML. Respond with just the HTML code property formatted, not wrapped in markdown or any description of what is in the response.
There is probably some room to iterate on the prompt for better output, but the cycle of testing (especially with different hand-written code) is long and not free, so I may stick with what is working reasonably well.


Overall, though I’m skeptical of the utility of LLMs more generally, it’s exciting to more easily and reliably make the kinds of quirky computer vision projects I’ve been dreaming of for a long time. I’d be interested in smaller handwriting OCR specific models that I might be able to run locally someday!